How to manually change the order of legend and plot means and error bars
It is a good practice to let the legend follow the trend of the data. Like in the figure below, the legend is also ordered from "Top 20" to "Bottom 80%".
 Another example in which the legend is ordered from high to low by the values in 2010:
Another example in which the legend is ordered from high to low by the values in 2010:

Depends on how to code is organized in ggplot2, there are different ways to change the order:
1. Sometimes just reorder the levels of the factor is enough:
2. Sometimes relevel the factor doesn't work, then we need to manually assign it using "scale_..._discrete(breaks = ...)" in ggplot.
Maybe it is because in this case the statistics shown in the figure are obtained using "stat_summary " directly.
How to prepare the dataset:
The helper function in this cookbook is very helpful. It talks about how to use ddply in a function to return the statistics we need. And dataframe must be supported to this function. Variables shall be supplied with a quote: "var" as arguments.
c("year", "PDETS") is the same as .(year, PDETS) as an argument.
Example
# a self-defined function to calculated weighted mean, sd, se, CIs, could be improved as I set na.rm = T.


The rest are technical notes.
Depends on how to code is organized in ggplot2, there are different ways to change the order:
1. Sometimes just reorder the levels of the factor is enough:
# reorder the factor
m4_mean_all_2$Group <- factor(m4_mean_all_2$Group,
levels =c('Top 20%','In Total', 'Bottom 80%'))
# plot the top20 by group
ggplot(data=m4_mean_all_2, aes(x=year, y=wm, group=Group,
color=Group, shape=Group))+
geom_point(size=4)+
geom_line(size=1)+
geom_errorbar(aes(ymin=CI_low, ymax=CI_high), width=.2)+
ggtitle("Urban Density Change Over Time in Colombia") +
labs(x="Year", y="Average City Density", color = "", shape="")
# Moreover, we can use labs(x="Year", y="Average City Density", color = "", shape="") to suppress the dafault legend by color and shape seperately.2. Sometimes relevel the factor doesn't work, then we need to manually assign it using "scale_..._discrete(breaks = ...)" in ggplot.
Maybe it is because in this case the statistics shown in the figure are obtained using "stat_summary " directly.
# manually assigned order
region_order <- c("Land-Rich Developed Countries (LRDC)",
"Sub-Saharan Africa (SSA)" ,
"Western Asia and North Africa (WANA)",
"East Asia and the Pacific (EAP)" ,
"Latin America and the Caribbean (LAC)",
"Southeast Asia (SEA)" ,
"Europe and Japan (E&J)" ,
"South and Central Asia (SCA)"
)
ggplot(data=univ_long, aes(year, Population, group=Region, color=Region, shape=Region))+
stat_summary(fun.y = median, geom='line') +
stat_summary(fun.y = median, geom='point', size = 3) +
labs(x="Year", y="Median City Population")+
scale_color_discrete(breaks = region_order) +
scale_shape_discrete(breaks = region_order)How to prepare the dataset:
The helper function in this cookbook is very helpful. It talks about how to use ddply in a function to return the statistics we need. And dataframe must be supported to this function. Variables shall be supplied with a quote: "var" as arguments.
c("year", "PDETS") is the same as .(year, PDETS) as an argument.
Example
# a self-defined function to calculated weighted mean, sd, se, CIs, could be improved as I set na.rm = T.
# a function to calculated weighted mean, sd, se, CIs
weighted_Output <- function(x, w){
N = sum(!is.na(x))
wm = weighted.mean(x, w, na.rm = T) # weighted mean
m = mean(x, na.rm = T)
m_of_w = mean(w, na.rm = T) # mean of the weights
median = median(x, na.rm = T)
if (N > 1) {
sd = sqrt(sum(w*(x - wm)^2, na.rm = T)/(N-1)/m_of_w)
} else {
sd = NaN
}
se = sd/sqrt(N)
CI_low = wm - qt(0.975, df=N)*se
CI_high = wm + qt(0.975, df=N)*se
return(list(n=N, m=m, wm=wm, sd=sd, se=se, CI_low = CI_low, CI_high = CI_high))
}
# weighted_Output(Sample200$DensityUET3, Sample200$UrbanExtentT3 )
# it is indeed complicated to supply variables to ddply, must supply df.
# output e.g.: Region n mean sd CI_low CI_high
get_WM_and_CI <- function(dataset, fac, var, w){
CI_output <- ddply(dataset, fac,
function(dataset, var){
w_output = weighted_Output(dataset[,var], dataset[,w])
n = w_output$n
wm = w_output$wm
sd = w_output$sd
se = w_output$se
CI_low = w_output$CI_low
CI_high = w_output$CI_high
return(c(n, wm, sd, se, CI_low, CI_high))},
var)
# This is for 0 or only 1 fac. variable
names(CI_output) <- c('Region', 'n', 'wm', 'sd', 'se', 'CI_low', 'CI_high')
return(CI_output)
}
# for >1 groups, print name directly
get_WM_and_CI2 <- function(dataset, fac, var, w){
CI_output <- ddply(dataset, fac,
function(dataset, var){
w_output = weighted_Output(dataset[,var], dataset[,w])
n = w_output$n
wm = w_output$wm
sd = w_output$sd
se = w_output$se
CI_low = w_output$CI_low
CI_high = w_output$CI_high
return(c(n, wm, sd, se, CI_low, CI_high))},
var)
names(CI_output) <- c(paste(fac),'n', 'wm', 'sd', 'se', 'CI_low', 'CI_high')
return(CI_output)
}
m4_mean1 <- get_WM_and_CI2(Co_long, c("year", "PDETS"), "Density", "UE")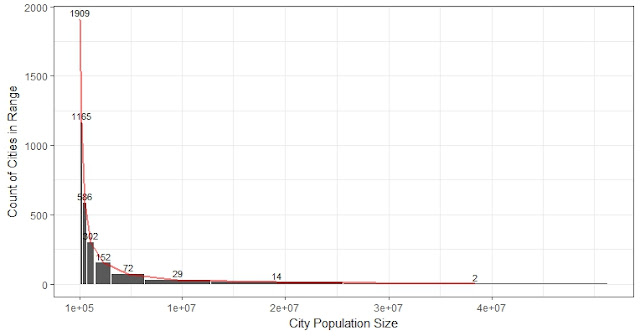

Comments