Week 3/19 How many jobs are passed on the way in Chicago?
Revised on Mar.25th, calculation of jobs passed was not correct.
3.21 - 23 (Fri)
Since Wednesday I have been working on a problem that looks similar to the global conflict score I calculated before. We have the coordinates of both start points (home) and end points (work) of 3.5 million commuting trips in Chicago. One trip can carry more than one person, the total number of people on all the trips is 3.7 million. So each trip is weighted, but the average number of persons on each trip is merely 1.07.
(Notice that statistics on distance-related variables obtained from a 1% random sample is quite representative of the population, with mean = 19.7, weighted man = 19.18)
Visualization of 35,040 (1%) randomly sampled trips: (longer trips are marked in yellow, shorter trips are marked in red.)

* The histogram of travel distance, skewed to the right not too extreme.

* People living in the peripheral do travel longer distances
Visualization of travel distance for people from home on the map of Chicago. Darker red shows places where people living there travel longer distances:



* People working in the city center do not necessarily travel a long distance
On the other hand: Do people working in city center travel longer? It doesn't seem to be so.
Visualization of travel distance for people at work on the map of Chicago. Dark red shows places where people work there travel long distances:



3.20 (Tue) Used R markdown to generate reports for road and block
3.21 - 23 (Fri)
Since Wednesday I have been working on a problem that looks similar to the global conflict score I calculated before. We have the coordinates of both start points (home) and end points (work) of 3.5 million commuting trips in Chicago. One trip can carry more than one person, the total number of people on all the trips is 3.7 million. So each trip is weighted, but the average number of persons on each trip is merely 1.07.
1. Most trips in the dataset were done by only one person
The distribution of the weights: number of people on each trip between each pair of origin and destination are highly skewed to the right: the busiest trip had 109 persons traveling from Indian Village to the University of Chicago. Actually, the top 13 trips (853 persons) all target somewhere in the University of Chicago (coordinate: 41.78937, -87.60285). On the other hand, 95% of the 3.5 million trips have only 1 person, 99.6% of the trips have 3 or fewer persons.2. The average travel distance for all the trips is 19 km.
It is easy to get the travel distance for all the 3.5 million trips. The mean is 19.728 km, the weighted mean is 19.181 km, the median is 15.262 km, sd = 15.98 km, min = 0 km, and max = 141 km.(Notice that statistics on distance-related variables obtained from a 1% random sample is quite representative of the population, with mean = 19.7, weighted man = 19.18)
Visualization of 35,040 (1%) randomly sampled trips: (longer trips are marked in yellow, shorter trips are marked in red.)

- See next post for technical details about how this is done using ggmap in R.
- See this post for further discussions on how to use heatmap to produce a proper visualization on home and job densities.
* The histogram of travel distance, skewed to the right not too extreme.

* People living in the peripheral do travel longer distances
Visualization of travel distance for people from home on the map of Chicago. Darker red shows places where people living there travel longer distances:

Besides a heat map, I also tried 3d surface using wireframe function from R package lattice. I attached the code in the next post.

Not too surprising, most people work close to home. But those living on the periphery will travel a longer distance. People living in city center travel relatively shorter trips.

* People working in the city center do not necessarily travel a long distance
On the other hand: Do people working in city center travel longer? It doesn't seem to be so.
Visualization of travel distance for people at work on the map of Chicago. Dark red shows places where people work there travel long distances:


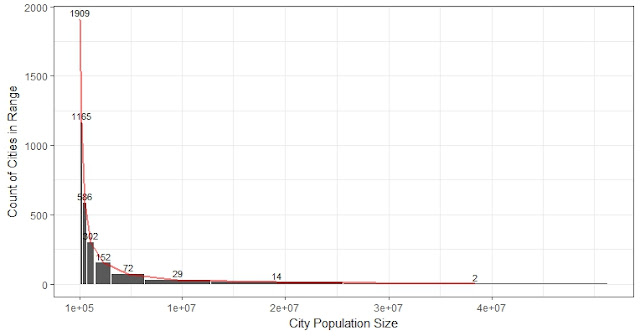
3. How many jobs have been passed to reach one's job?
To measure the integration of the job market in the city, we are interested in the number of opportunities bypassed by each passenger to reach his job (a foraging index). In another word, we suppose that if someone travels a long distance, it is because he doesn't want or cannot get the nearby jobs.
- On average, a commuter has passed 23% of all the jobs in Chicago.
- Based on 35,040 (1%) random sample of trips, which contains 37,244 jobs in total:

The maximum number of jobs passed is close to total jobs in the sample. Mean = 7,649 (jobs), weighted mean = 8,418 (jobs), median = 4,944, min = 0, max = 37,240, sd = 9,298.
Min. 1st Qu. Median Mean 3rd Qu. Max.
0 1091 4944 8685 13771 37240
Based on 350 K (10%) random sample which contains 373 K jobs:
Every statistic is roughly 10 times the results from 1% sample.
Min. 1st Qu. Median Mean 3rd Qu. Max.
0 10765 49491 86594 136634 373094
So the percentage of job passed by a traveler on average are the same: 86,594 / 373,000 = 23%.
4. Challenges during programming
I adopt the similar code to calculate the number of jobs passed as the one for conflict score. I wrote some distance function and used mapply in r to calculate for each person (each point), its distances to all the other points, and sum those within his distance to work. But this time there are 3.5 million locations to go through. (conflict score was on a scale of < 10k). I anticipated that the code I wrote might take too long since running on a testing subset of 10k takes several minutes. I first tried to improve the program, which did not improve anything. Then I tried packages written by others to get distance matrix then timed the vector of weights to obtain the vector of "job passed" directly, which looks neat but takes much longer when the matrix size is over 10k.
(Comments 3.27) Now calculating 350 K records took 7 hours. 3.5 M would take maybe a month. So the limit of this approach is about 1 million trips.
--------------------------------------
3.19 (Mon) Re-ran all the figures for the Colombia paper3.20 (Tue) Used R markdown to generate reports for road and block


Comments